Neural Sign Language Translation
2024
My high school, Burnaby South, was home to the only Deaf high school in British Columbia. Having taken ASL for over three years made me aware of how much communication between Deaf and hearing students still depended on typing on phones or relying on interpreters. With the goal of helping my Deaf and hearing friends more easily communicate, I set out to build a two-way translation system between American Sign Language and English that respects ASL as a complete language rather than a visual form of English. Most tools stop at speech-to-text or fingerspelling and assume the burden of translation lies on Deaf users. My goal was to allow someone signing to be understood in spoken English, and someone speaking to be understood visually in ASL—without forcing either to switch languages, and without relying on written English as an intermediary.
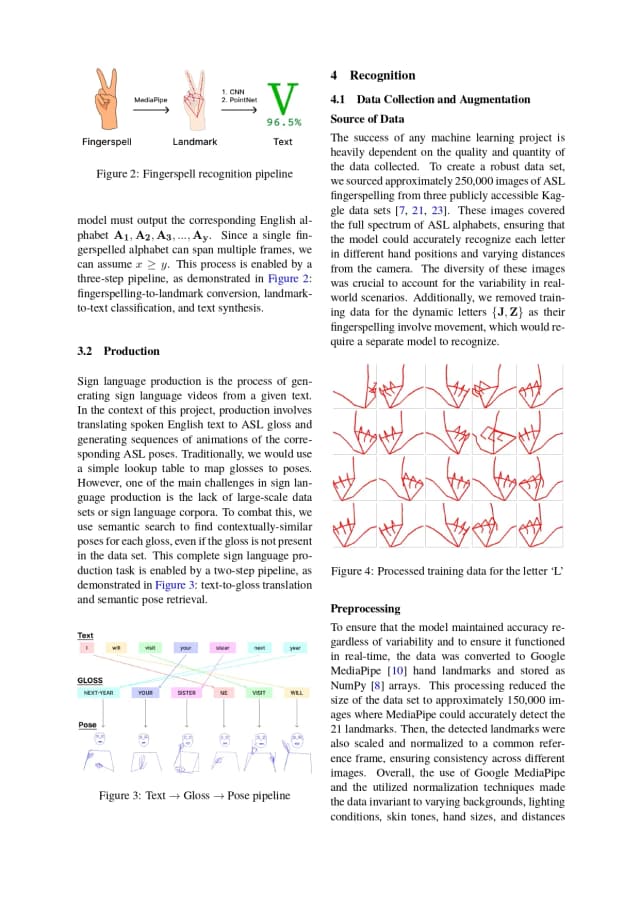
For reception (ASL -> English), I used MediaPipe to extract 21 three-dimensional landmarks per hand. Each frame becomes a structured point cloud of 63 values, normalized relative to the hand to remove bias from camera distance or hand size. Then, after preprocessing datasets of over 120,000 labeled examples from multiple ASL datasets, I trained two models to predict letters frame by frame: a PointNet classifier, and a custom CNN classifier. After, to make individually classified characters more legible, I developed a synthesis layer that groups those predictions into words by requiring temporal consistency across frames before accepting a character, filtering noise and classification errors, and using GPT-4o-mini to correct commonly confused letters using spatial heuristics.
For the expressive pipeline (English -> ASL), I constructed a database of roughly 9,500 ASL signs from online databases, and stored them as time-series landmark animations of hands and upper body, captured using MediaPipe Pose and Hand tracking. Then, I used a MiniLM model to embed the spoken English representations of these signs into a 384-dimensional vector space, allowing me to query the database for the most similar ASL signs to a given English word (which helps combat the limited vocabulary of ASL signs I had access to). I stored both the embeddings and the timeseries motion data in PostgreSQL with pgvector for fast cosine similarity queries, allowing me to continually retrieve and replay the most similar ASL signs to a given English word in real time. Finally, if a spoken word has no exact match, the system falls back to fingerspelling. A custom ThreeJS frontend renders the retrieved motion sequences as a 2D signing avatar in real time.
While this prototype effectively allowed for real-time communication between Deaf and hearing students at my high school, it does not come even close to capturing the entire nuance of ASL—facial expressions, non-manual signals, grammatical structure, and a lot more. However, it served as a modular SDK that could be extended and deployed on any application. Over the next few months, I applied the SDK to a few different projects, including a Chrome extension for real-time ASL interpretation of YouTube videos.